【开普云AI实践(八)】DiT架构在AI视频生成中的创新应用
AI视频生成技术作为人工智能领域的一个重要分支,近年来取得了显著的进步。随着人工智能生成内容(AIGC)技术的迅猛进步,作为其核心组成部分之一的视频生成技术,正在重新定义传统视频制作与创作的边界。这一技术融合了计算机视觉、自然语言处理等多领域的研究成果,赋予了人工智能理解并创作高质量动态影像的能力。本文旨在剖析基于AIGC的视频生成技术当前的发展态势、背后的关键技术(DiT)以及该领域未来可能的发展方向与潜在变革。

目前,AIGC视频生成领域主要采用Transformer、Diffusion Model和二者结合的DiT路线,其中DiT已成为主流方向,兼顾扩展性和生成质量。
DiT,即Diffusion Transformer,是一种新型的扩散模型,它将传统扩散模型中的U-Net架构替换为Vision Transformer(ViT),并针对Diffusion Model特点修改模型,旨在提升图像生成性能。扩散模型的核心思想是通过将图像逐渐转换为噪声并反向还原。在该过程中,噪声估计网络负责估计添加的噪声,并引导模型去噪。大多数传统扩散模型使用U-Net作为骨干架构,而DiT通过Transformer架构替代U-Net,显示出Transformer在生成任务中的潜力。
DiT模型在视频生成领域的一个典型应用是Wan模型,它是一种先进的视觉技术模型,能够生成高质量、逼真的视频内容。Wan模型的核心组件包括Diffusion Transformer(DiT)、Variational Autoencoder(VAE)和Vision Transformer(ViT),其中DiT负责从噪声数据中恢复出原始的视频数据。

DiT模型的基础架构与Vision Transformer(ViT)类似,但针对扩散过程进行了优化。它使用了自适应层归一化(AdaLN)层来注入条件输入,如扩散时间步或类别标签。这些AdaLN层显著提升了模型的生成质量,并在去噪过程的残差连接前进行激活调制,使模型在生成视频时更加准确和高效。
Diffusion Transformers(DiTs)是一种新型的扩散模型,它利用变换器(transformer)架构代替了传统扩散模型中常用的U-Net骨干网络。DiTs的设计灵感来自于视觉变换器(Vision Transformers,ViTs),ViTs已证明在视觉识别任务中比传统的卷积网络更加有效。
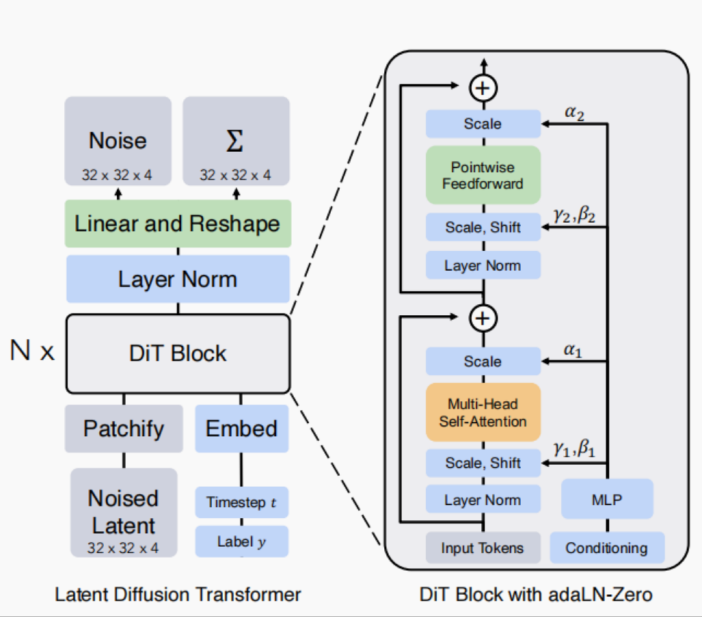
图一 DiT模型架构图

目前基于DiT的视频生成模型中,生态最为繁荣、效果最佳的开源框架为通义万象Wan。Wan 基于 Diffusion Transformer(DiT)和 Flow Matching 框架,设计高效架构,通过创新的时空(spatio-temporal)变分自编码器(VAE)提升文本可控性与动态建模能力。模型使用超过万亿 tokens 的图像与视频训练,在运动幅度、质量、风格多样性、文本生成、摄像机控制等方面均展现强大能力。
Wan模型基于 Diffusion Transformer(DiT)架构设计,包含自研时空变分自编码器 Wan-VAE、Diffusion Transformer 主干、文本编码器 umT5,以及一系列推理加速与内存优化机制。 Wan-VAE,专为视频生成而设计。通过结合多种策略,改进了时空压缩,减少了内存使用,并确保了时间因果关系。Wan-VAE 在性能效率方面相比其他开源VAE具有显著优势。此外,Wan-VAE 可以对不限长度的1080P视频进行编码和解码,而不会丢失历史时间信息,使其特别适合视频生成任务。
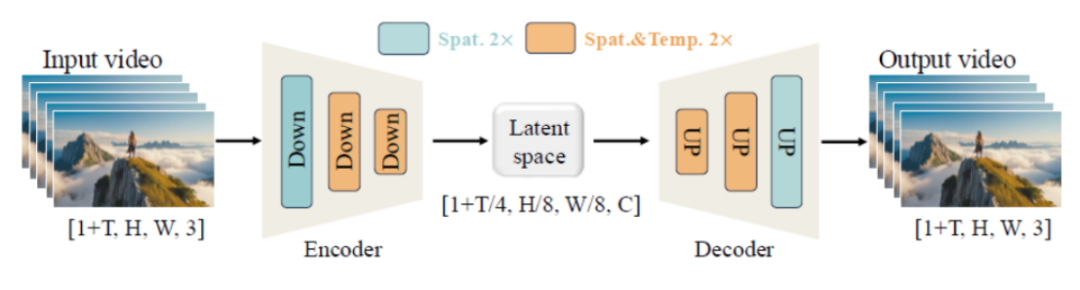
图二 Wan的VAE框架
为支持长视频推理,引入 chunk-based 特征缓存机制:每个 chunk 对应一组潜变量,缓存前一 chunk 的特征以实现上下文连续;默认设置下使用2帧缓存,支持因果卷积;对于2×时间下采样场景,采用1帧缓存与零填充。该机制可推理任意长度视频,且在显存使用上优于传统方法。

图三 特征缓存机制
Wan主干采用DiT架构,包含Wan-VAE(视频编码)、 Diffusion Transformer、文本编码器 umT5(多语言支持强,收敛快)、视频经 VAE 编码为潜变量,后由 DiT 生成。训练阶段包括:低分辨率图像预训练(256px),构建跨模态对齐能力;图像-视频联合训练,按分辨率逐步升高(192px → 480px → 720px);使用 bf16 精度与 AdamW 优化器,初始学习率 1e-4,动态衰减。沿用预训练配置,在高质量后训练数据上继续训练,进一步提升视觉细节与运动建模。
Wan 针对大模型训练的高资源消耗问题,设计了一系列优化策略,包括工作负载分析、并行策略、显存优化及集群稳定性保障。
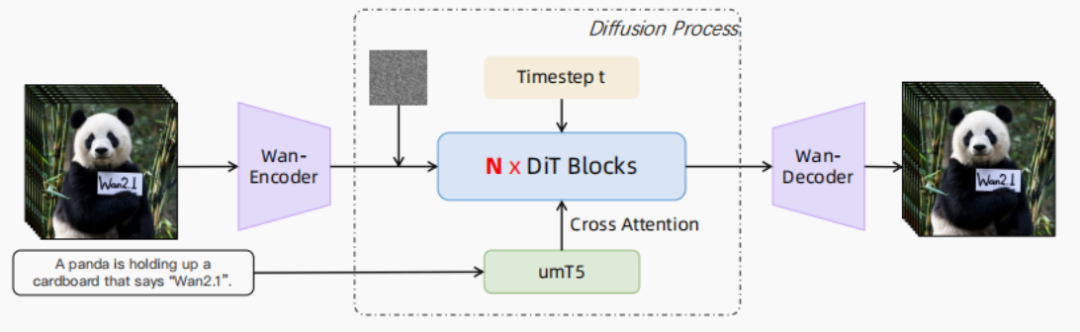
图四 Wan视频生成框架
AI视频生成技术已在影视制作、广告营销、在线教育、虚拟人交互等多个行业展现出广阔的应用前景,开普云自研的开悟多模态内容生产平台采用了当前主流的视频生成技术路线——DiT,并融合Transformer、扩散模型与多模态理解的先进架构,为用户提供文生视频、图生视频等创作工具。经过开普云创新研发,开悟多模态内容生产平台生成的视频在画质、时序连贯性、语义可控性等方面实现了突破,为AI视频生成技术的广泛应用提供了全新的智能化、个性化体验。








